发布时间:2019-11-18 作者: 王维嘉
11月11日,人大重阳与人大商学院合办了人大重阳系列讲座No.184《对话名家王维嘉:暗知识——机器认知如何颠覆商业和社会?》,王维嘉博士是人工智能最早的研究者和移动互联网的开拓者。现将精彩演讲呈现如下(全文有删减,详情可参阅其著作《暗知识》)。
编者按:11月11日,人大重阳与人大商学院合办了人大重阳系列讲座No.184《对话名家王维嘉:暗知识——机器认知如何颠覆商业和社会?》,王维嘉博士是人工智能最早的研究者和移动互联网的开拓者。现将精彩演讲呈现如下(全文有删减,详情可参阅其著作《暗知识》)。
摘要
王维嘉博士首先为大家介绍了自己写作《暗知识》这本书的初衷——为读者呈现一本通俗易懂且实用的人工智能读本。之后由AlphaGo下围棋取胜开始介绍人工智能如何走进大众视野,以及人工智能的内在逻辑和基本原理。虽然目前人工智能有很多震撼的应用和表现,但有时就连工程师本人都很难解释其中的原因,这是因为人类对于知识的理解、描述和传播受到自身生理条件的限制。一直以来人类掌握两类知识:“明知识”和“默知识”,而今天,人工智能突然发掘出了“暗知识”——隐藏在海量数据中的万事万物间的关系。对于暗知识的理解和运用有助于我们认识人工智能的核心技术和本质、明确区分to B和to C,从而能够甄别未来哪些行业将被人工智能颠覆、存在投资的机会,又有哪些领域充满泡沫和陷阱,人工智能未来的发展瓶颈是什么;对于普通大众来说,虽然一些涉及大量数据搜索和整理的工作将会被人工智能取代,但那些充满创意和人文情怀的事物则永远是人类的精神所在。
要点汇总
知识可以分成三类:“明知识”“默知识”和“暗知识”。明知识就是可以用语言、文字或公式清晰表达和描述的知识;默知识则是个人在感觉上能把握但无法清晰描绘的知识,即我们常说的“只可意会,不可言传”的那类知识;暗知识是隐藏在海量数据中的万事万物间的关系,既无法感受又无法表达和描述的知识。
暗知识告诉我们,你的直觉、经验,虽然难以解释,但不是迷信,是有科学根据的。特别是我们理解人类大脑工作原理以后马上就能理解了,因为这个信息在我们头脑中。神经元的连接是非常复杂的,而我们语言能描述的东西非常少,所以我们经常说语言是非常贫乏的。
AI浪潮与互联网浪潮有三个区别:一是AI从一开始就要颠覆传统行业;二是技术驱动和商业模式驱动的区别;三是可能不会出现平台性公司或“赢家”通吃的局面。
判断一个行业AI能否落地,有三个要素:第一是行业本身是否会产生大量的数据;第二是这些数据要足够复杂、丰富、有意义;第三是这个行业能吸引足够的资金支持。

一、为什么写《暗知识》这本书?
市场上人工智能的书已经非常多了,我自己的日常工作是在硅谷管理一家风险投资公司,每天花时间最多的是看项目、投资,每年大概要看上千个这样的项目。我发现市场的书有两类,一是技术专家写的,写得非常非常技术,相信大家肯定看过公式、推导,别的一般人看不懂,连我这样有技术背景的人都看不懂;二是写市场营销的东西,主要是写应用和未来,这种书对做实业的人,无论是政府管理还是企业管理,用处并不是很大。我就想能不能写一本书,第一能够在技术上用最简明、通俗的语言把它讲清楚,让没有任何技术背景的人能够看懂。第二,能让这本书有用,比如作为投资人我能够知道哪些行业能投,哪些行业不能投,对其他行业有什么作用。
二、人工智能是怎样进入大众视野的?
人工智能进入我们的大众视野是因为AlphaGo下棋这件事儿,为什么下棋这件事儿对大家的震撼很大呢?特别是在中国,下围棋是聪明人玩的游戏,像我这样的智力连一段都下不了,但AlphaGo居然把九段大师全部无情地碾压。比如聂卫平,为什么AlphaGo在盘中那么走的,他不懂,一直走到最后才知道这是一步非常高的棋,Google的工程师也不懂。AlphaGo打败了人类以后,Google的工程师又造了一台机器叫AlphaGoZero。第一台AlphaGo是先学人类的几万盘残局,然后把人打败了。AlphaGoZero不学人类的残局,只学围棋规则,互相对弈,看能不能打败原来的AlphaGo,结果七天以后它就打败了原来的AlphaGo。这件事儿对我们的震撼就更大了,这意味着什么?人类的经验不仅没有帮助,反而是累赘,这让我们的自尊心受打击太大了。为什么?不知道。
三、解密人工智能的黑箱
现在整个人工智能产业遇到一个问题——它做出了非常神奇的结果,但不知道为什么,是个黑盒子。很多人试图解释,但怎么都解释不了。这时候我就在想,会不会真的有一类知识是我们人类根本没法理解的。我们回答这个问题之前可能有点学术的定义,就是“什么是知识?”以前翻译字典,给出的知识定义非常多,我这里给出简单的定义“知识就是数据之间的关系”,大家仔细想想,我们生活中就是这样的道理。比如我们教孩子,让他学会认英文字母“O”,怎么教会这个孩子认识英文字母O呢?当你在纸上画出一个圆圈,他能发出O的音来,或者发出O的音后,他能在纸上画出O来。就是把孩子的音和图形建立了联系,他就学会了字母O。我们很多知识都是这样的道理。
有了这样的定义,我们来看一下,事物之间都有哪些关系。所有事物之间就有两类关系,一类叫做因果关系,一类叫做相关关系。在历史上关于人类认知,有两个学派,一个是理性主义,认为万事都有因果,还有一派叫经验主义。最后他们谁都说服不了谁,为什么呢?就是因为,他们都在讨论认识论,但都不了解人脑是怎么回事。
人脑是怎么工作的呢?下图是人脑神经的一个神经元示意图。我们脑子里有多少神经元呢?1000亿个,就是通过突触连接起来。它的工作原理也非常简单,一个神经元的突触它们之间传的是电信号,怎么传呢?把化学分子传过来之后,这边接收化学分子,变成电压,就把两个神经元连起来。所以,今天人类所有的思维活动,学习的基础,就是我们神经元之间建立了联系。比如说小孩学字母O。他的视觉神经元和听觉神经元两个建立起联系来,我每次看到一个椭圆就能够激发那个声音的神经元,就能够把这个声音发出来。其实人类学习的主要原理就是这个道理。这个原理是什么时候发现的呢?70年前。

神经元示意图,图源:http://www.sohu.com/a/315500512_661013
当发现神经元工作原理的时候,一批电脑科学家说这个原理很简单,我能不能用电子线路来模拟呢?完全可以。下面这张图就是用一个电子的线路来模拟人脑的神经元。这个符号“Σ”是加号,我有很多输入信号,我把输入信号加起来,和一个门限比较,门限就是我定一个电压,比如0.8V,把三个加起来,高于0.8就把神经元打开,低于就关掉。整个工作原理就这么简单,一个加法器+一个门限。今天看到的所有非常神奇的人工智能,它的基本工作单元就是这个,从1956年开始到今天都没有变化,就是这样最最简单的基本原理。
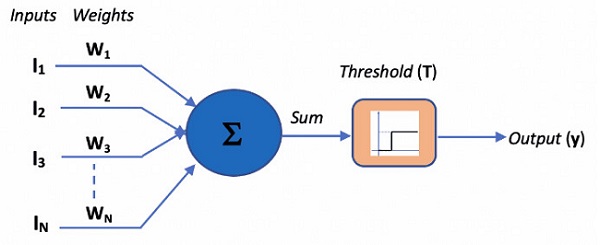
图源:https://kite.com/blog/python/artificial-neural-networks/
我斯坦福的博士导师在1959年做出了世界上第一个可以调节系数的神经元,是一个比较大的黑盒子。整个盒子就一个神经元。今天科技发展到什么程度呢?一颗芯片上就可以有几百万个神经元。当你只有一个神经元时,只可以做一些科学的演示或像游戏一样的东西。当有几百万个神经元时我们就可以下围棋,做更复杂的东西。今天我们听到过很多词,比如深度学习,神经网络,什么叫深度学习呢?我把很多神经元,一层层地堆起来,每一层互相连起来,如果有很多层,这就叫多层的神经网络,也叫深度学习的神经元。

图源:https://blog.godatadriven.com/rod-multi-threshold-neuron
今天机器可以做人脸识别,假如我让机器识别汽车,怎么训练它呢?给它看不同的汽车图片,每个汽车图片让它给我输出一个信号,告诉我是1还是0,如果是1说明它认识了,如果是0我就调上面的旋钮,一直让它输出1为止。当它看了很多照片以后,慢慢就抓住了汽车的特征,比如汽车有4个轮子,汽车的颜色等,我再给它看新的照片,它就能认出汽车。猫也是同样的道理。今天大家说数据的学习和训练,就是给机器看很多已知的图片,告诉它,这张是汽车,下张也是汽车,然后它就记住了。有点像教小孩一样,教他这是苹果,以后他看到就知道这是苹果。很多的过程都有很多数学计算在里面,但它的基本原理就是这样的。
神经网络大家觉得很神奇,我今天就想把这个神秘的面纱给揭掉。它每个组成单元都非常简单,一个加法器一个比较器,就这两个东西。每个神经网络里都有百万、千万个神经元,要想把这些神经元数学表达式写出来几乎不可能,因为它是个高阶的方程,非常难以解析。对普通人来讲最重要的是理解它的最基本特征——它能够从数据当中,把数据之间的相关性给提取出来。所以,我说它是“一头辛勤工作的AI的奶牛”,吃进去的是数据,挤出来的是相关性。提取数据的相关性就是今天神经网络最本质的东西。但它的局限性也来自它这个本质。
我们在媒体上看到各种各样的大词“人工智能、机器学习、神经网络、深度学习”,他们包含的关系是这样的:人工智能是最大的框,第二个框是机器学习(人工智能里还有一部分是非机器学习,非机器学习就是所谓的专家系统,比如我做自动驾驶,就想能不能把开车总结成一条条规则,比如见了红灯我就停,见到绿灯我就行,见了行人我就躲。结果发现根本没有办法把驾驶所有的场景都写下来,其实人类在三四十年前就试过这个办法,走不通,因为实在是太复杂了。)机器学习是什么呢?不写规则。今天的自动驾驶把每一幅驾驶场景照成照片,拍成视频告诉机器这种场景应该怎么做,前面有3个小孩,有50米,你要踩刹车了,前面有人,有红灯,你要停了。把所有的场景拍成照片,让机器自己从里面总结出规律和相关性来,这就是所谓的“机器学习”,对普通人来讲,这四个词是可以互换、通用的,人工智能就是指机器学习,就是指神经网络。但还有一类知识是人类无法理解的,那些只可意会不可言传的知识。
四、直觉是迷信吗?
到70年前,我们才突然发现,除了可以用文字记录下来的知识以外,还有第二类知识——那些“只可意会,不可言传”的知识。
比如面试一个新的员工,这个人到底靠不靠谱,怎么判断呢?有经验的面试官坐下来三五分钟基本就有大概的印象,但为什么觉得这人靠谱或者不靠谱,你说不出来,就是一种感觉。
同样的道理,我们在企业里,在政府里,当碰到重大决策的时候,我们就说请老板拍板。为什么叫“拍板”呢,为什么做决定的时候要一咬牙一跺脚呢?原因是信息不完备,当你有一个决策所需要的所有信息时,任何人都可以做决策,机器也可以。而现实是所有的重大决定都是在信息不完备的时候做的,怎么做呢?只能根据经验和直觉。所以,索罗斯说过一句话,“我所有的重大决定都是靠我的胃做出来的,如果我的胃疼,就说明这个决定不好,也就是说我的身体是有感应的。”大家生活中有这样的常识,如果我面对重大决定不知道怎么做的时候,就扔硬币。有时候你扔完以后说不行我得再扔一遍。为什么你会再扔一遍?因为你潜意识不喜欢扔出来的这一面,也就是你心里已经做出了决定。所以,有一句话说“当你无法做决定的时候就扔硬币,直到你心里想要的那一面出来为止。”
过去我没法理解,觉得这些直觉、经验都是迷信的,都是不科学的,因为说都说不清楚。其实我们今天理解人类大脑工作原理以后马上就能理解了。因为这个信息在我们头脑中,神经元的连接是非常非常复杂的,但我们语言能描述的东西非常少,所以我们经常说语言是非常贫乏的。这涉及到一个关键概念:暗知识。
五、知识的四个象限与暗知识
刚才我们已经讨论了可以用符号记录下来的知识和只可意会不可言传的知识。但人工智能发现的知识,比如Google下围棋这种知识是不是一类既不可意会也不可言传的知识?我们可以把人类的经验和表达用两个轴(分为四个象限)表达出来,几乎可以把人类所有的知识放在这个框架里。

第一类,既可感受也可表达。例如我们初中物理都学过浮力定律,牛顿三定律里作用力和反作用力,只要敲一下桌子手指就会疼,这些既可以感受也可以表达,非常清晰。
第二类知识是属于可表达不可感受,这里最典型的是爱因斯坦的广义相对论和20世纪发现的量子力学等。
第三类是只可意会不可言传(可感受,不可表达)的知识,像骑自行车。既不可感受也不可表达的就是“暗知识”,上图把人类或者世界上所有的知识全部包括在内了。
总之,能用文字表达的知识叫“明知识”,大量的感觉、经验等达不出来的默知识就是水面下的冰山,它的总量远远大于我们能说出来的东西,“暗知识”就是整个海洋,它的量又要远远大于其他两种知识。

六、AI投资落地的六大关键
(一)理解人工智能产业的生态金字塔
我们做投资时第一个要做的功课就是理解这个产业的生态,什么叫生态呢?就是一个产业有哪些组成部分,这些组成部分之间是什么关系?这些组成部分各自产生什么样的价值?这些不同的组成部分谁的砍价能力是什么样的。当一个项目到我面前时,我马上可以把它在产业生态里做个定位,马上可以知道它会受哪些因素的影响和牵制,而不是你这个技术好,你这个人好,你这个市场大,我一定要投资。
我总结出来的一个金字塔图。在金字塔最顶端的是算法,就是理论、逻辑,神经网络是怎么构建的;第二层是芯片,不管什么样的东西都要用芯片,电脑要用芯片,手机要用芯片,人工智能要用芯片;第三层是软件平台,这个平台就是一些程序库。现在有很多开源软件,比如我在程序库里做了一件事儿以后,发现这个模块很多人都会用,我就把它贡献到开源社区里,其他人就不用再写一遍了,后面这些人把这些程序库拿起来,堆在一起,就不用从头去写一行行代码,这就是所谓的开源社区。
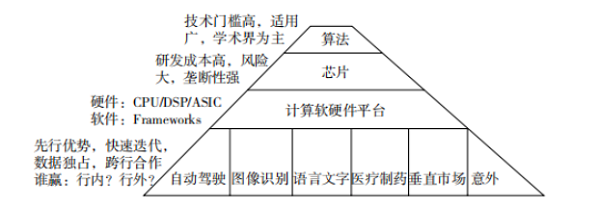
很多人都问我,中美人工智能怎么比较?在基础的算法、芯片和软件平台上,现在美国肯定是领先的。美国在人工智能方面研究已经60多年了,我们才开始追赶。美国的英特尔已经有非常强的芯片基础。在计算软件平台方面,现在最大的开源社区就是Google,Google的TensorFlow有全世界最大的软件社区,包括中国的工程师也在上面开发。所以,在基础设施和核心技术上,美国是领先的。但应用上各国就有各有千秋了。比如中国的人脸识别绝对是全世界领先,领先到什么程度?美国在后面跟着吃土的资格都没有,为什么呢?市场非常大。在美国、欧洲几乎没有市场,或者市场非常小,只有一些垂直的应用,而中国市场特别大,市场一旦大了以后,技术就可以发展得非常快。自动驾驶,中美各有千秋。对于中国,我很看好医疗图像识别。
(二)哪些行业适合人工智能的三个标准
第一,这个行业本身会产生大量的数据,不论是它的生产流程还是服务流程还是管理流程。
第二,这些数据要足够复杂和丰富,比如我这里放一台空气净化器,一直发声音,你把声音录下来也是数据,但这个数据有没什么意义,非常单调,没有意义。
第三,这个行业要有钱,你没有钱的话别人不愿意改造你和颠覆你,颠覆你的目的是为了赚钱。
(三)明白To B 和 To C 的区别
这两者最主要的区别是:互联网是to B的生意,人工智能是to C的生意,一个是面向消费者,一个是面向企业和政府,有的叫to G,其实都一样,就是一个对机构,一个对个人。这对我们做大的判断有什么影响呢?第一,to C的生意有赢者通吃的特点,比如现在有个微信,马云想再做就很难。阿里有个淘宝,你想做淘宝第二就很难,因为它有网络效应,淘宝上商家越多,用户越多。微信上朋友都在上面,再做个新东西我不愿意转过去,因为我朋友都在这儿,这种网络效应使得to C的生意变得赢者通吃。
人脸识别就是To B的生意。比如一个公司把北京的人脸识别市场拿起来,但他能不能把上海市场拿下来和北京没关系,如果在上海还有个构思和你差不多的,人家就能把上海拿下来,甚至可能比北京还要强。所以,to B的生意不会产生赢者通吃,这造成今天AI里的泡沫。为什么AI今天有泡沫呢?一个原因,很多投资人把互联网时代的投资思维带到了AI时代。在互联网时代如果你发现一个头部公司,不管淘宝还是滴滴,不管多贵我就抢进去,只要能进去就能赚钱,基本规律就是这样,因为最后赢者通吃。现在大家觉得还是赢者通吃,以很高的价钱进去,发现没有赢者通吃,因为不值那么多钱,它的市场份额不像互联网to C那样具有垄断地位,所以也就产生了泡沫。
抖音就是To C的生意,很快就在全世界做起来了,非常快。但to B的生意就没有那么快,我记得李开复说,未来的人工智能,中国和美国是全世界最领先的,其他的欧洲、日本都会被远远落在后面。这个话对不对呢?我们看一下to B和to C的生意,比如今天的互联网公司,一旦有了美国的Google,欧洲就做不出搜索引擎,一旦有了美国Facebook,(欧洲)也做不出来。而一个消费品应用会被全世界的消费者迅速接受,比如iPhone。
而to B就会有壁垒。比如现在要给巴黎市做个人脸识别,需要跟巴黎市的警察局合作,假如有一家法国公司,他的技术和你一样好,你觉得警察局更可能选这个法国公司还是选一个美国公司,还是选中国公司呢?更大的可能是选择本地公司,因为过程中要接触大量的警察局的数据,要做各种系统集成和定制化的东西,需要本地大量的沟通,有文化的东西。所以,这种对政府和对企业的生意,它的壁垒,国家之间的壁垒就非常高,就不可能出现像Google、Facebook、抖音这样世界性的应用,一定是区域化的。
另外一个就是同类技术的竞争问题,大家都用美国的芯片,大部分要依赖Google的开源软件。其次是有没有聪明人的问题。法国没有聪明人吗?法国人的数学非常好;俄国没有聪明人吗?日本没有聪明人吗?韩国没有聪明人吗?任何一个国家都能找出成千上万个数学天才,然后很快找出这些算法,很简单,没有什么壁垒。所以,一旦它是to B的生意以后就会带来这些不同的变化。这就是我说的,当你理解了它一个基本特点以后,就能做出很多推断出来,对你未来的投资发展会做出很大的判断。比如现在有个美国公司告诉我说,我做人脸识别将来打遍全世界,我根本不相信他,因为我有这样的基本判断,这对我的投资是非常有用的。

(四)人工智能难以替代企业家精神
我们把市场、供给和需求做个轴,已知和未知做个轴,在已知的需求市场上,数据是绝对有用的。比如矿泉水市场,因为今天中国矿泉水的消费基本上不会有什么大的增长或大的减少,因为每天你就能喝这么多水,再有钱也不会多喝两瓶水,也不会穷到连水都喝不起。这个数据肯定是可以收集起来的,在已知的需求里,大数据非常有用。
但经济是需求拉动的吗?不完全是,也可能是供给打动的,所以我们现在叫“供给侧改革”。比如矿泉水的包装颜色比较保守,瓶子的设计不太时尚,水是不是能放点维生素?所以,虽然是个已知的需求,仍然可以从供给侧做大量的改进。我作为企业家觉得市场很大,一定能做出一个非常时尚的瓶子,就卖给20岁左右的人,现代人就讲这种感觉。所以,在已知的供给方面实际上可以做很多很多改进,也就是创新。这些东西在谁的脑子里呢?在企业家脑子里。企业家不会满街说我要做这个东西,说也没用。此外,更重要的一点是做这样的创新不是有想法就可以了,而是你要真正承担财务风险。比如你做出一个带酸味的矿泉水结果发现根本没人喜欢这个味儿,根本卖不出去,那就是靠运气赚的钱全凭实力就给赔掉了。
也就是说在供给方面,大数据是预测不了的,因为它在人的脑子里。至于到未知方面,就是未知的需求和未知的供给,大数据、人工智能就更难以发挥作用。比如乔布斯2007年做的iPhone。假如2006年到人大,抓住人就问你希望智能手机有什么功能?谁能回答这个问题?没有一个人能回答得了这个问题,因为你根本不知道什么叫智能手机,也没有这个需求。所以,乔布斯说,我的市场调查就是出门的时候对着镜子看自己,我根本不做市场调查,完全就靠脑袋想。大家说,乔布斯太神了。我在硅谷待了35年,其实在乔布斯之前,不知道多少家公司在这个方向上折戟沉沙,做掌上电脑,手写识别,包括苹果公司早期的相关产品都赔了不少钱。到了乔布斯的时候,所有的星星都排成一条线了,他的运气来了,因为技术到了那个临界点,到那个时候一下就成功了。所以,很难了解未知的需求。就像特斯拉发明电动汽车一样,所有人都觉得电动车就是玩具,人家就做出来了。所有未知的需求和供给都永远藏在企业家、创新家、发明家的脑子里,而且是通过试错,大量的失败完成的,一将功成万骨枯。
我的结论是,人工智能、大数据不管计算能力多强大,收集多少数据,都不可能代替企业家的精神,不可能代替人类的创新,不可能代替试错。
(五)谨慎预测未来风口
2007年有一场大讨论: 移动互联网对互联网是延伸还是新的物种? 以搜索为例,有人说无非在手机上装了一个搜索条,多了一个屏幕而已,运营上没有什么区别,这很有道理。另外一部分人就不同了,说手机和PC是完全不一样的东西,第一,手机永远跟着你,第二,手机有位置信息。我属于后一派的。当时有人说能做和PC互联网不一样的应用吗?大家知道,如果做出新的应用来,肯定会是因为这两个特点。果不其然,今天我们最大的应用是什么?微信。为什么微信好用呢?就因为老跟着你。第二是滴滴打车,为什么有滴滴打车?因为有位置信息。这两个和PC不同的特征造成了巨大的新的应用,但在十年前谁都看不到,谁要说他能看到,那是骗子或疯子。当然,也有可能他蒙对了。

(六)当前人工智能的瓶颈
人工智能有哪些局限性呢?它现在有点像动物,狗鼻子非常灵,认路认得非常准,但让它学开车实在勉为其难,比如人类学家曾经花了很大功夫去训练黑猩猩学人类的语言,怎么学都学不会,它可以认出一些词,比如香蕉、吃,但永远无法用语法组织起来,哪怕从小跟着人生活它也学不会。所以,我把它叫作没有符号,没有情感,没有意识。因为它没有自我意识,不懂得什么是爱,什么是恨,没有疼痛的感觉,也没有死亡的恐惧,什么都没有。所以,我认为它取代不了我们人类的这种因果推理,逻辑推理,更取代不了大量需要情感的工作。比如医生、老师、管理者,很多需要人类同理心,同情心的工作机器根本取代不了。我见到很多机器人公司,他们说要做个机器人保姆,我看都不看。一个保姆做的工作是何等复杂。不光机器做不了,而且还差得很远,保姆是最难被机器人取代的。
在人工智能领域为什么大家觉得恐慌呢?因为大家觉得人工智能这么神奇,下围棋把人类打得一塌糊涂,未来再发展下去是不是能控制人类,使我们成为它的宠物呢?大家想想,在它能成为我们的主人之前有个前提,它要产生自我意识,什么叫自我意识?我知道我的存在,我知道我和世界的不同,这种自我意识是怎么产生的?没有人知道。所以,今天人类有三大问题还没有得到回答,宇宙怎么起源的,生命怎么起源的,自我意识怎么起源的?这三大问题都不知道,没有答案。我们现在知道的是什么呢?意识是个进化的产物,在人类进化中,不知道哪个基因一搭,一突变就产生了意识。其实大家想想,为什么今天我们的天文望远镜已经看出几千、几万光年,在我们已知的几千亿星球里根本找不到我们人类这样的智慧生物呢?原因就是,我们这种智慧生物是无数次的运气的累加才能到今天。
以前的人工智能无非是延长我们的腿、眼睛、耳朵、肌肉。今天的人工智能是延长我们的大脑,至少大脑的一部分功能会被它大大增强。所以,是人类历史上一次无比重要的工具进化,而且它一定会深刻全面地影响我们生活的方方面面。所以,今天如果我们能够理解它的本质,理解它给我们带来的变化的话,我们就能更好地应对未来。(欢迎关注人大重阳新浪微博:@人大重阳,微信公众号:rdcy2013)
























 京公网安备 11010802037854号
京公网安备 11010802037854号